.H), fonte
(.C), objecto (.o), biblioteca ou arquivo (.a),
e executável.inline.namespaces).
Modularização em pacotes.
Desenhar no quadro o código abaixo. Dizer para não passarem!
No primeiro semestre fomos sempre desenvolvendo programas que consistiam num único ficheiro C++. Hoje vamos ver que é possível um programa consistir em vários ficheiros.
A divisão de um programa em vários ficheiros permite aquilo a que se chama "compilação separada". Tem várias vantagens face à solução de um ficheiro único:
A modularização física corresponde à divisão de um programa em ficheiros. Infelizmente, os módulos deste nível de modularização são conhecidos por módulos simplesmente, o que se pode tornar um pouco confuso. Dependendo do contexto, a palavra "módulo" pode ter o seu sentido lato (um módulo qualquer, que pode ser uma rotina, uma classe, um módulo físico ou um pacote) ou o seu sentido estrito de módulo físico.
Os módulos físicos correspondem tipicamente a um par de ficheiros ditos fonte: o ficheiro de implementação (com extensão .C) e o ficheiro de interface ou cabeçalho (de extensão .H). No primeiro indica-se como se usam e o que fazem as ferramentas disponibilizadas pelo módulo, i.e., o seu contrato, e no segundo implementam-se as ditas ferramentas. Quem consome o módulo normalmente apenas usa directamente o ficheiro de interface.
Finalmente, os pacotes são tipicamente constituídos por vários módulos físicos, com ferramentas relacionadas. Em C++ os pacotes não são suportados directamente. Mas existe uma construção sintáctica no C++ que permite organizar as ferramentas quase como num pacote: os espaços nominativos.
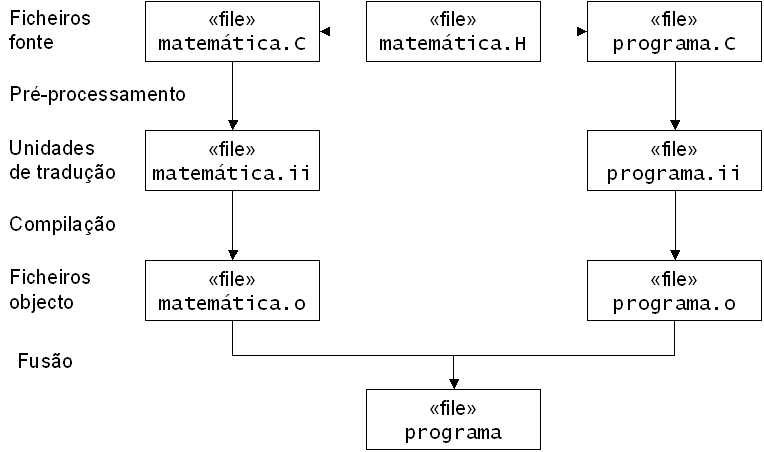
Quer a modularização física, quer os espaços nominativos, são assunto desta aula. Antes de avançarmos, porém, vamos estudar as várias fases da construção de um programa (um ficheiro executável) a partir de vários módulos.
programa.C:
#include "matematica.H"
#define TURMAS_GRANDES
#ifdef TURMAS_GRANDESint const número_máximo_de_alunos = 100;#elseint const número_máximo_de_alunos = 30;#endif
int main(){int notas[número_máximo_de_alunos];...cout << média(notas, 10) << endl;}
matematica.H:
double média(int const m[], int const n);
matematica.C:
Dizer que o ficheiro
#include "matematica.H"
double média(int const m[], int const n)
{double soma = 0.0;for(int i = 0; i != n; ++i)soma += m[i];return soma / n;}
programa.C está gatado, pois
não tem #include <iostream>. Pedir-lhes para imaginarem
que se podia usar o cout de qualquer forma...
Dizer ainda que faltam instruções de asserção, etc. A ideia é reduzir o código ao mínimo essencial para mostrar o que se pretende.
A construção de um ficheiro executável a partir de um conjunto de ficheiros fonte passa para 3 fases:
Note-se que "compilação" é apenas uma das fases da construção! É típico usar o termo "compilação" para o processo completo, e temo-lo feito até agora, mas em rigor é incorrecto.
O pré-processamento pega num ficheiro fonte, tipicamente num
ficheiro de implementação .C, e gera ficheiro pré-processado,
com extensão .ii. A um ficheiro de implementação
pré-processado chama-se uma unidade de tradução. A unidade de
compilação continua
a conter código C++, mas o pré-processador faz-lhe algumas
alterações. O comando para pré-processar é:
O compilador pega numa unidade tradução e tradu-la para linguagem máquina. Mas não gera um ficheiro executável! Gera um ficheiro objecto, que além de conter o código máquina contém informação adicional acerca desse código máquina. Os ficheiros objecto têm extensão
c++ -E programa.C -o programa.iic++ -E matematica.C -o matematica.ii
.o.
O comando para compilar é:
c++ [opções] -c programa.iic++[opções]-c matematica.ii
Explicar que na segunda versão a compilação é precedida pelo pré-processamento.c++ [opções] -c programa.Cc++ [opções] -c matematica.C
Explicar opções de compilação: -Wall -g -ansi -pedantic
Note-se que a compilação age sobre um único ficheiro! Daí que se fale em compilação
separada: os ficheiros de implementação, .C, são
pré-processados e depois são compilados separadamente...
O fusor é que funde todos os ficheiros objecto do programa e gera o ficheiro executável.
Vamos ver cada uma destas fases mais em pormenor:
c++ -o programa programa.o matematica.o
O pré-processor copia do ficheiro de implementação .C para
a unidade de tradução .ii, mas sempre que encontra uma linha começada por #
interpreta-a: essas linhas contêm as chamadas directivas de pré-processamento.
O pré-processador é uma ferramenta pré-histórica que se mantém no C++ por causa das suas origens no C... Há muitas directivas de pré-processamento, mas só algumas nos interessam.
Explicar #include. Explicar diferença entre <> (ficheiro
de interface "oficial") e "" (ficheiro de interface "nosso"). Dizer
que um ficheiro depois de incluído é também pré-processado, e por isso pode ter
outras inclusões.
Explicar vagamente macros como "constantes" do pré-processador.
Explicar compilação condicional. Dizer que nas aulas práticas se verá uma melhor aplicação para ela.
A compilação de um ficheiro C++ já pré-processado, ou seja, a compilação de uma unidade de tradução, consiste na sua tradução para linguagem máquina. É feita em pelo menos três passos:
O resultado da compilação não é apenas código máquina. É algo mais. Simplificando grosseiramente as coisas, o ficheiro objecto resultante da compilação contém duas tabelas: uma das disponibilidades, e outra das necessidades.
Explicar que o ficheiro programa.o tem na tabela das disponibilidades
a função main() e na das necessidades a função
média(). Por outro lado o ficheiro matematica.o tem na tabela
das disponibilidades a função media() e na tabela das necessidades
não tem nada.
Cada ficheiro objecto, por si só, não é executável.
Por exemplo, ao ficheiro matematica.o falta a função
main()
e ao ficheiro programa.o falta a função média(). A informação
do que cada ficheiro objecto tem e do que necessita é o que possibilita
ao fusor fazer o seu trabalho.
Na fase da fusão os ficheiro objecto são todos fundidos num único executável.
Fazer boneco mostrando as três fases que evidencie bem as compilações separadas e a fusão final.
O fusor basicamente concatena o código máquina de cada ficheiro objecto depois de verificar que:
main(), pois de outra forma não
se poderia criar o executável.Dizer que mesmo no semestre passado não trabalhavam só com um ficheiro!
O programa mais simples tem pelo menos um #include e precisa de ferramentas
da chamada biblioteca padrão do C++. O que acontece é
que o fusor funde os nossos ficheiros objecto automaticamente com a biblioteca.
Mais, nós podemos criar as nossas próprias bibliotecas!
Podemos pegar num conjunto de ficheiros objecto e arquivá-los num
ficheiro de arquivo ou biblioteca: prefixo lib e extensão
.a.
Para arquivar ficheiros objecto não se usa o fusor: usa-se o arquivador. O programa arquivador invoca-se normalmente como se segue:
Explicar vagamente
ar ru libarquivo.a ficheiro_objecto.o...
r e u. Replace e update.
Já vimos como era feita a compilação separada.
Vamos voltar à modularização física.
Um módulo físico corresponde tipicamente a dois ficheiros
fonte: o ficheiro de implementação e o de interface.
É normal que o módulo onde está a função main() não
tenha ficheiro de interface. Assim, no nosso exemplo temos dois módulos
físicos:
matematica: ficheiros fonte matematica.C e matematica.Hprograma: ficheiro fonte programa.CA primeira pergunta é mais difícil de responder duma forma taxativa. Mas pode-se dizer que cada módulo deve corresponder a um conjunto muito coeso de rotinas, classes, etc. É típico que um módulo corresponda a uma classe apenas e algumas rotinas associadas a essa classe. Por vezes há mais do que uma classe, quando essas classes estão muito interligadas. Por vezes não há classe nenhuma, como no nosso módulo matemática, que provavelmente só conteria rotinas para operações matemáticas.
A outra pergunta é mais fácil de responder. Em cada módulo, o que se coloca no ficheiro de interface e o que se coloca no ficheiro de implementação? Ao ficheiro de interface só deve ir parar aquilo que é estritamente necessário para se poder usar o módulo. Em particular:
inline.inline.inline._impl.H.
Repare-se que, mais uma vez, os módulos são caixas pretas (que ocultam uma implementação no ficheiro de implementação) com uma interface bem definida (no ficheiro de interface).
E falta falar do nível de modularização seguinte: os pacotes.
Explicar problema da colisão de nomes. Dar exemplo com empresa que compra duas bibliotecas de funções, uma para lidar com a logística e outra com a contabilidade e que quer usá-las simultaneamente num programa.
Verão Software:
logistica.H...
void consolida();
...logistica.C...
void consolida()
{...}
...liblogistica.a:
logistica.o
Inverno Software:
contabilidade.H...
void consolida();...
contabilidade.C...
...
void consolida()
{
}
...libcontabilidade.a:
contabilidade.o
Explicar que os ficheiros de implementação não são fornecidos! Estão no segredo dos deuses.
O nosso programa é:
programa.C:
#include <contabilidade.H>#include <logistica.H>
int main(){consolida();}
Qual das versões do procedimento é invocada?
Explicar o que acontece quando se usa:
c++ -o programa programa.C -llogistica -lcontabilidade
A compilação tem sucesso, pois a forma de fundir os arquivos pára a pesquisa quando encontra o procedimento, não pesquisando os seguintes!
Se se tivesse acesso aos ficheiros objecto:
c++ -o programa programa.C logistica.o contabilidade.o
a fusão daria um erro por definição duplicada!
Que fazer? Pedir aos fornecedores para alterarem o nome do procedimento? E eles mudam? E quanto tempo levam?
O C++ tem um mecanismo que evita este problema da colisão de erros e que, simultaneamente, pode ser usado para agrupar as ferramentas num nível mais elevado de modularização: os espaços nominativos (name spaces).
Podem-se colocar vários módulos físicos num mesmo espaço nominativo (e vice-versa, mas não é tão útil...). Por exemplo, se as empresas fornecedoras (Verão Software e Inverno Software) tivessem sido mais competentes, todos os módulos das suas bibliotecas estariam num espaço nominativo correspondente ao nome da empresa. Por exemplo:
Verão Software:
logistica.H
namespace VerãoSoftware {
...
void consolida();
...
}logistica.C...
void VerãoSoftware::consolida()
{...}
...
Inverno Software:
contabilidade.H
namespace InvernoSoftware {
...
void consolida();
...
}contabilidade.C...
void InvernoSoftware::consolida(){...
}
...
Agora a nossa empresa não tem problemas. Pode escrever:
Explicar directiva de utilização para passar todos os nomes para o âmbito de visibilidade corrente. Explicar versão menos dramática da declaração de utilização. Relembrar
#include <contabilidade.H>#include <logistica.H>
int main(){VerãoSoftware::consolida();InvernoSoftware::consolida();}
std::. Dizer que o registo de sociedades garante
que não há duplicação de nomes a nível nacional. Mas a
internacional... Pode-se usar outro espaço nominativo pt,
por exemplo, que é o símbolo internacional de Portugal.
Cada uma dessas empresas podia ter na biblioteca vários pacotes (cada um com vários módulos físicos), com objectivos diferentes. Nesse caso cada um teria espaços nominativos diferentes:
Verão Software:
logistica.H
namespace VerãoSoftware {
namespace Logística {
...
void consolida();
...
}
}logistica.C...
void VerãoSoftware::Logística::consolida()
{...}
...
Inverno Software:
contabilidade.H
namespace InvernoSoftware {
namespace Contabilidade {
...
void consolida();
...
}
}contabilidade.C...
void InvernoSoft::Contabilidade::consolida(){...
}
...
Agora a nossa empresa pode escrever:
#include <contabilidade.H>#include <logistica.H>
using namespace VerãoSoftware;using namespace InvernoSoftware;
int main(){Logística::consolida();Contabilidade::consolida();}
Dizer que os ficheiros de interface também podem ter nomes
coincidentes. Por isso deve-se adoptar a estratégia de os colocar em
directórios correspondentes ao espaço nominativo a que pertencem. Por
exemplo pt/VerãoSoftware/Logística/logistica.H.